Audio annotation is crucial for projects that aim to develop AI systems capable of understanding human speech, natural language, or environmental sounds.
5+
Years on the market
1000+
Successfully implemented projects
1000+
Independent Annotators
24/7
Support Availability
90%
hold BS, MS, or PhD in Math/Computer Science
Key Features of our Audio Annotation Services
High-quality Speech & Audio Annotation Services to Scale your AI Models
#1
Model Flexibility Through Multilingual Audio Annotation
Our expert audio annotation services empower your AI models with flexibility across hundreds of languages, dialects, demographics, and environmental scenarios. We capture high-quality audio and speech samples tailored for any AI-enabled live audio application or speech recognition system.
#2
Audio Quality Enhancement and Optimization
Beyond data collection, we refine your audio samples by applying advanced noise reduction and signal enhancement techniques. Our specialists ensure that every audio clip meets rigorous quality standards, improving overall performance for voice-enabled machine learning applications.
#3
Audio Content Summarization and Captioning
Expand your audience reach with our innovative audio summarization and captioning services. We generate clear, concise summaries and captions for audio content, incorporating speaker identification and precise time stamping, ideal for accessibility and content indexing in multiple languages.
#4
Comprehensive Speech and Audio Data Classification
We categorize and annotate audio files based on detailed project specifications. Our classification services cover acoustic data, recording quality, background noise, speaker intent, and more, ensuring that every sample is accurately labeled for optimal use in AI and machine learning projects. o3-mini
4-Step Process for Audio Annotation
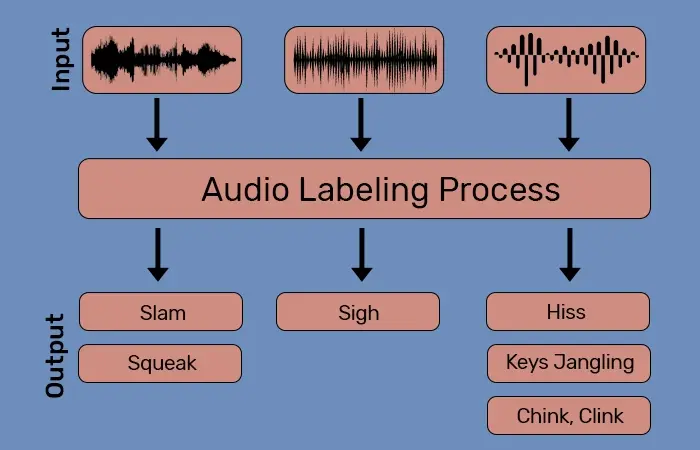
Step 1: Sound Labeling
We begin by identifying and classifying various sounds—such as speech, background noise, and music—using a combination of advanced AI audio labeling tools and manual methods. This precise tagging allows users to quickly search and locate specific sounds within audio recordings, saving time and resources.
Step 2: Event Tracking
Next, we analyze and segment audio recordings into distinct events. Leveraging both software and human expertise, we annotate these segments to facilitate rapid identification of key occurrences, whether for monitoring communications, investigating activities, or tracking specific audio events.

Step 3: Speech-to-Text Transcription
In this stage, we convert spoken content into text while enriching the transcription with critical contextual information. Factors such as the speaker’s gender, age, accent, and ambient background noise are annotated, ensuring that the transcription accurately reflects the audio's nuances and improves overall comprehension.
Step 4: Audio Classification
Finally, we assign detailed labels to audio recordings based on their content. This may include descriptors like genre, artist, emotion, and sentiment. Utilizing both manual efforts and AI-powered tools, our expert team ensures that every audio file is accurately categorized, making it easier to retrieve and analyze data for various applications.
Use Cases

Voice Assistants & Smart Devices
Our audio annotation services fine-tune voice recognition and natural language processing models, ensuring that smart assistants and devices accurately interpret diverse accents, dialects, and ambient sounds for seamless user interactions.

Media and Entertainment
Enhance content discovery and audience engagement with precise audio labeling. Our services empower media platforms to efficiently index podcasts, interviews, and music, facilitating targeted advertising and improved reachability.

Security and Surveillance
Strengthen security systems with high-quality audio annotation designed for surveillance and monitoring. Our services enable the detection of unusual sounds and anomalies, enhancing real-time alerting and ensuring a safer environment through advanced audio analytics.
FAQs
1. Time-consuming: Audio annotation takes up a lot of time as it’s performed manually. AI models that are able to transcribe or label audio data instantly lack accuracy. They still aren’t capable of tackling varied aspects of speech data.
2. Expertise: Native language experts are required for annotating and labeling data. Experienced people are required for labeling it as speech data is complex in nature.
3. Requires an Annotation Platform: Right tools are necessary for performing tasks on audio files including segmentation, transcription, speaker identification, filler words, speech labelling, intent annotation and sentiment annotation.
4. Crowd Management: With the growing AI ecosystem, working on different varieties of audio annotation projects in various languages will become a necessity. In such cases, collaboration will become a necessity.
5. Quality of Data: Annotating audio files which have heavy background noise, bilingual speakers, etc. is a complicated task, so having a varied speech dataset for building robust AI is a necessity.
We use verbatim transcription—a detailed, word-for-word transcription—to capture every spoken word in an audio file. This method is commonly employed to train automatic speech recognition (ASR) models.
Our strict quality assurance processes and extensive annotator training guarantee high precision. We utilize advanced quality control measures to ensure every audio annotation meets the highest standards, prioritizing your project's success.
Interested in Joining Our Team?
In today's tech-driven world, a career in Artificial Intelligence (AI) can be highly rewarding. Join our team of Annotation Specialist, and be a part of the company that creates high-quality training datasets.
Get in Touch with us
 Vietnam Office
Vietnam Office
102 Tran Phu, Mo Lao, Ha Dong, Ha Noi
 Give Us A Call
Give Us A Call
+84 812-436-211
