Fine-Tuning and Its Transformative Impact on LLMs' Output
 By Label Forge | 27 August, 2024 in Generative AI | 4 mins read
By Label Forge | 27 August, 2024 in Generative AI | 4 mins read
Large language models have transformed how we interact with machines with their capability to match human intelligence. However, they don’t always produce output that meets the requirements of specific tasks or industries. Fine-tuning is the process of enhancing the performance of a pre-trained large language model for more precise and relevant outputs. In this article, we will discuss how different fine-tuning options, including supervised, unsupervised, and instruction-based techniques, enable LLMs to adapt to specific tasks to generate effective outputs.
What is Fine-tuning?
Large language model fine-tuning refers to the process of improving a pre-trained model’s performance for specific tasks or domains with the objective of achieving the desired output. Fine-tuning is instrumental in guiding a pre-trained model for domain-specific applications, as the model might lack understanding of the specific context, taxonomy or specialized knowledge that aligns with the domain.
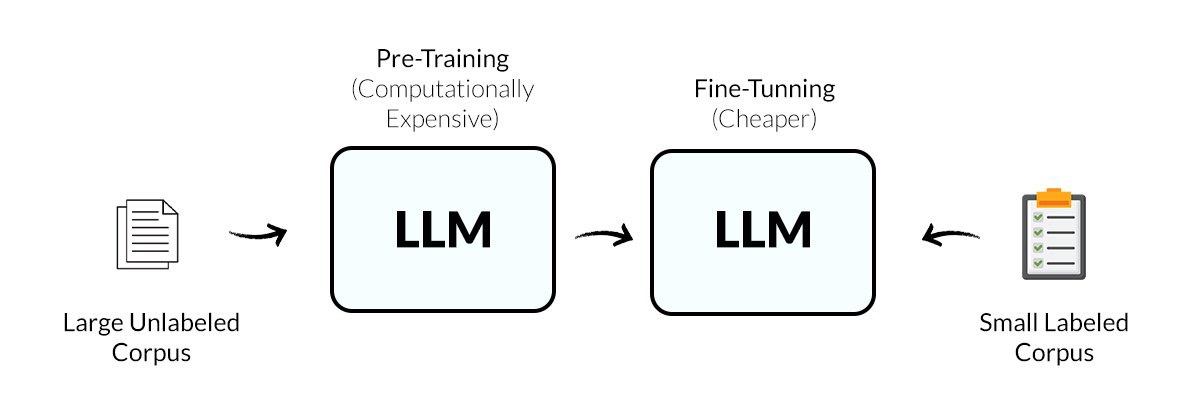
Fine-tuning vs. Pre-training
Pre-training is the first step, which involves training the model from scratch on large corpora scraped from the internet, books and social media. This phase provides the model with the ability to acquire the general understanding of language, syntax, and factual information and generate human-like content.
Fine-tuning is the advanced phase that employs more domain-specific datasets to fine-tune the model’s parameters, customizing it to the specific nuances of a task or domain. The technique significantly enhances the model’s knowledge, aligning it with particular industry standards.
While pre-training lays a strong foundation for a model's ability, fine-tuning is critical to making that foundation effective for a particular task or domain compared to a general-purpose pre-trained model.
Why is LLM Fine-Tuning Required?
LLM fine-tuning is necessary for several reasons, especially when deploying models in domain-specific applications. While pre-trained LLMs can effectively capture general language patterns from a massive corpus, that doesn’t guarantee optimal performance within specialized domains. Fine-tuning optimizes a models’ performance to suit the specific application or task better. Fine-tuning is essential for the following reasons:
Model customization: Each industry or organization uses specialized language or terminology. By fine-tuning an LLM on industry-specific datasets, it can generate output that aligns with the specific needs of that field, such as medical research or legal documentation, making it more accurate and useful.
Data compliance: The evolution of large language models has raised concerns about privacy and compliance. Fine-tuning addresses these issues by training a large language model on compliant data, mitigating compliance and privacy concerns.
Limited annotated data: In some cases, a pre-trained model might need more annotated data for a specific task or domain. Fine-tuning allows organizations to optimize pre-existing labeled data more effectively by customizing a pre-trained model to learn the particular patterns and nuances of tasks, enhancing the model’s utility and performance.
Types of LLM Fine-Tuning
LLM models can be refined in different ways depending on the specific goals. Here are three standard fine-tuning methods:
Unsupervised Fine-Tuning: A large amount of unlabelled data from the target domain is used to refine LLMs through unsupervised fine-tuning. The model analyzes the unlabeled data to identify patterns and relationships between words and phrases within the domain-specific data, learning how often certain words are used together in a specific context. Ultimately, the model refines its understanding of the language in the target domain. For example, understanding the frequency of terms like ‘plaintiff’ and ‘defendant’.
Supervised Fine-tuning (SFT): This technique involves training the model on task-specific labeled datasets where each piece of input data has a corresponding correct answer or label attached. Supervised fine-tuning guides the model in adjusting its parameters to predict the labels, using its pre-existing knowledge acquired from pre-training to the specific task. As it trains the model to map inputs to the desired outputs, it is an efficient and effective technique for tasks such as translations, classification, and NER (name entity recognition).
For example,
Pre-trained LLM: Input: “I can’t log into my net banking account. What to do?”
Output: “Try resetting your password clicking on the ‘Forgot Password’ option.
Fine-tuned LLM: Input: “I can’t log into my net banking account. What to do?”
Output: “We are really sorry to hear that you are having trouble logging in. Visit the login page and try resetting your password using the ‘Forgot Password’ option.”
Instruction Fine-Tuning: This method focuses on providing clear instructions to the LLM in natural language. In other words, instruction fine-tuning techniques enable AI models to perform various tasks by simply giving them instructions. The model learns to understand and interpret these instructions to execute specific tasks without requiring a large corpus of labeled data for each task. For example, you can provide instructions like “Write a response to the customer experiencing internet banking related issues.” Instruction fine-tuning reduces data dependency and provides more control over the model’s behavior. However, poorly designed prompts can impact the model’s performance and its ability to generalize.
The Impact of Fine-Tuning on LLMs' Output
Fine-tuning significantly improves the quality and relevance of responses generated by LLMs. It customizes the model’s output for specific tasks or domains, boosting accuracy, reducing errors, and improving the user experience. For example, a fine-tuned LLM in the finance field can more accurately analyze historical data, identify patterns, and predict potential market downturns as it is trained to understand financial terminology and context.
Challenges and Limitations of Fine-Tuning
LLM fine-tuning has its limitations and unique set of challenges that must be navigated.
Risk of Overfitting: Fine-tuning raises the risk of overfitting, where the model becomes too specialized and loses its ability to generalize across different tasks or domains. Implementing cross-validation and techniques like regularization can help fine-tune the model without compromising its ability to perform well on new or unseen data.
Data Requirements: High-quality, domain-specific data is required to fine-tune generative AI models. Obtaining data can be challenging, especially in highly regulated industries such as healthcare.
Resource Constraints: Fine-tuning, especially large language models, can be resource-intensive, necessitating significant computational power and time.
Conclusion
Fine-tuning is a powerful technique for tailoring LLMs to specific needs, enhancing accuracy and relevance in specialized tasks. By employing various fine-tuning methods, the model’s accuracy and applicability can be improved in specialized tasks or domains. Effective techniques help achieve high performance with minimum resource consumption. Eventually, fine-tuning methods and techniques can adapt a general-purpose model for a specialized field, driving innovation and resource efficiency.
please contact our expert.
Talk to an Expert →
You might be interested

- Generative AI 16 Jan, 2024
Understanding Generative AI: Benefits, Risks and Key Applications
Generative AI gleans from given artefacts to generate new, realistic artefacts that reveal the attributes of the trainin
Read More →
- Generative AI 22 Oct, 2024
The Impact of Unrepresentative Data on AI Model Biases
Unrepresentative data occurs when the training data fails to reflect the full scope of the input information and amplifi
Read More →
- Generative AI 13 Feb, 2025
Understanding Quality in Generative AI Training Datasets
Generative AI training, such as large language models (LLMs), requires extensive data to learn patterns, make prediction
Read More →